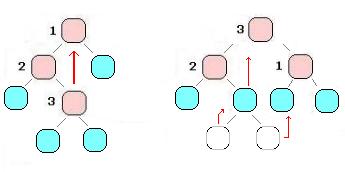
Veamos un ejemplo típico de algoritmo de Backtracking. Tenemos una serie de elementos únicos, cada uno con un peso o volumen ocupado, y cada elemento a su vez nos da cierta ganancia. Disponemos de una capacidad limitada por lo que debemos seleccionar de los elementos disponibles aquellos que nos den la mayor ganancia posible.
Supongamos que tenemos n elementos disponibles, numerados de 0 a n-1 y dos arreglos, uno p[n] que indica el peso de cada elemento y g[n] que indica la ganancia que nos da el elemento. M indica la carga máxima que podemos llevar. Debemos buscar elegir los elementos que nos den la mejor ganancia dado el espacio que ocupan.
Con estos datos pasemos a formalizar el problema.
Forma de la solución: Utilizaremos una tupla de largo n <x0,x1,…,xn-1>, donde cada elemento xi indica con 1 si llevamos el elemento i, o con 0 si no lo llevamos.
Reestricciones Explícitas: Cada elemento xi de la tupla se corresponde con un elemento i disponible.
Reestricciones Implícitas: La sumatoria de los pesos de los elementos seleccionados no superan la capacidad disponible M.
Función Objetivo: Maximizar la ganancia.
Predicados de Poda: Supongamos que en un momento dado encontramos una solución M_sol que es la mejor encontrada hasta el momento. Y supongamos que estamos construyendo una nueva solución parcial llamada sol. Dada esta solución parcial tendremos una poda si la suma de la ganancia que llevamos en la parcial, más las restantes que aún no hemos evaluado no llega a superar la ganacia de M_sol. Esto quiere decir que si la parcial tiene desde 0…k elementos, y nos quedan por analizar k…n-1, pero aunque eligieramos todos no llegamos a superar la ganancia de M_sol, no tiene sentido seguir con esta recorrida.
Terminada la conceptualización del problema, podemos pasar a construir la función que llamará al Backtracking:
int carga ( int* g, int* p, int* sol, int M) {
int pos = 0; // Posicion actual en la recorrida de elementos.
int ganancia = 0; // Ganancia parcial acumulada.
int m_ganancia = 0; // Mejor ganancia encontrada
int disponible = M; // Espacio disponible restante.
int restante = 0; // Ganancia restante disponible
int * parcial = new int[n]; // Marcaremos con 1 si llevamos al i, o con 0 en caso contrario
for (int i=0; i<n; i++) {
parcial[i] = 0; // Inicializamos en cero los eltos elegido.
restante += g[i]; // Ganancia de los elementos restantes, para la poda.
}
/* Llamamos a la función recursiva */
Back(g, p, parcial, ganancia, m_ganancia, disponible, restante, pos, sol);
delete[] parcial;
return m_ganancia;
}
Y veamos el código de la función recursiva:
void Back(int* g, int* p, int* parcial, int ganancia, int &m_ganancia, int disponible, int restante, int pos, int* sol) {
/* El primer paso es verificar que queda espacio disponible.
Ademas verificamos que podamos llegar a encontrar una mejor solución,
en caso contrario podamos. */
if ( (disponible > 0) && (ganancia + restante > m_ganancia)) {
/* Si ya pasamos por todos los elementos, terminamos */
if (pos == n) {
/* Ya sabemos que encontramos una mejor solucion que m_ganancia */
m_ganancia = ganancia;
for (int i=0; i<n; i++)
sol[i] = parcial[i];
/* Si no llegamos al final, probamos el elemento actual */
} else {
parcial[pos] = 1;
/* Probamos elegir el elemento y actualizamos los valores de ganancia y peso */
Back(g, p, parcial, ganancia, ganancia+g[pos], m_ganancia, disponible-p[pos], restante-g[pos], pos+1, sol);
parcial[pos] = 0;
/* O bien no lo llevamos y probamos seguir sin este elemento */
Back(g, p, parcial, ganancia, ganancia, m_ganancia, disponible, restante-g[pos], pos+1, sol);
}
}
}
De esta forma la función recursiva hace todas las combinaciones posibles de llevar ciertos elementos guardando el mejor resultados posible. Cada vez que se llega a pos == n es que recorrimos toda la secuencia, por lo que llegamos al final de la rama de decisiones del algoritmo. En ese momento y como el if que verifica que el espacio disponible sea sufuciente y que obtuvimos una mejor solución a la previa encontrada, podemos copiar el resultado obtenido.
Continuando con la serie de artículos sobre C/C++, vamos a ver la técnica de programación conocida como Backtracking. Esta técnica se basa en generar todo el espacio de soluciones posibles a un problema dado, pudiendo filtrarse o seleccionar las soluciones que cumplan con ciertas características. Backtracking funciona en forma recursiva, genera árboles de soluciones posibles, recorriendo todo el espectro de posibilidades.
En un primer vistazo Backtracking funciona como un algoritmo de fuerza bruta, que prueba todas las combinaciones posibles, aunque podemos optimizar y mejorar el rendimiento analizando el problema que queremos resolver.Los algoritmos de backtracking suele ser ineficientes, aunque mediante estas optimizaciones se puede moderar la misma, la repetición de cálculos hace que sean ampliamente inferiores a los algoritmos construídos sobre Programación Dinámica. En la próxima entrada analizaremos las diferencias, ahora volvamos a Backtracking :).
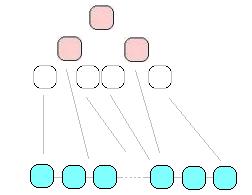
Por ejemplo, supongamos que tenemos un conjunto de colores y un mapa dado y queremos colorearlo, de forma que dos países adyacentes no tengan el mismo color. Podemos pensar en este problema como si fuera un grafo, donde los vértices conectados son los países limítrofes.
Este problema puede solucionarse de varias formas, por ejemplo buscando una solución cualquiera, o bien buscar todas las soluciones que existen, o bien la solución óptima que utiliza la menor cantidad de colores.
Lo primero que debemos hacer es formalizar el problema, así logramos identificar los elementos del mismo y se simplifica la tarea de construir el algoritmo. La formalización requiere definir:
Forma de la Solución: Cómo presentaremos la solución al problema. En este caso utilizaremos una tupla de largo fijo N formada por elementos xN, donde N es la cantidad de países que debemos colorear. En la posición 1 colocaremos el color asignado al país 1, en la posición 2 el color del país 2 y así sucesivamente.
Reestricciones Explícitas: El espacio de soluciones, o las soluciones posibles al problema, involucra a un único elemento de la tupla. En este caso indica que cada elemento xi es uno de los países a colorear.
Reestricciones Implícitas: Define las relaciones entre los elementos de la tupla, involucra a varios o todos los elementos de la tupla. En este caso debemos aplicar la reestricción que si dos países son adyacentes no deben tener el mismo color. Por lo que si 1 y 2 son adyacentes en el grafo, entonces los elementos x1 y x2 deben ser distintos.
Función Objetivo: Define lo que queremos maximizar o minimizar en las soluciones generadas. Puede ser la mínima o máxima cantidad de colores por ejemplo.
Predicados de Poda: Nos permite evitar buscar soluciones que es evidente no van a generar una solución útil. Por ejemplo supongamos que buscamos el mínimo de colores, entonces una vez que obtenemos una solución posible al problema sabemos que cualquier solución parcial que se esté construyendo puede ser descartada si la cantidad de colores supera a la ya encontrada.
Con estos elementos definidos podemos pasar a implementar el algoritmo con una idea general de como representar cada elemento. Lo primero que haremos será crear una estructura para nuestra tupla solución:
struct tupla {
int* colores; // Arreglo de colores asignados a los pasies
int* cantVeces; // Cantidad de veces que se usa cada color
int cantColores; // Cantidad total de colores usados
}
El próximo paso es preparar la invocación del algoritmo recursivo, al cual le pasaremos esta tupla para que trabaje:
void invocacion(int n, int k) {
/* La primera tupla será sobre la que se trabajará, en t solo guardamos la mejor solución obtenida */
tupla t, sol;
t.colores = new int[n];
sol.colores = new int[n]; // Colores asignados a los paises, n países
t.cantVeces = new int[k];
sol.cantVeces = new int[k]; // Cantidad de veces de cada color, k colores
for (int i=0; i<n; i++) {
t.colores[i] = 0;
sol.colores[i] = 0; // Inicializamos en cero los colores asignados a países
}
for (int i=0; i<k; i++) {
t.cantVeces[i] = 0;
sol.cantVeces[i] = 0; // Inicializamos en cero la cantidad de veces usada de cada color
}
t.cantColores = 0;
sol.cantColores = 0; // Cantidad de colores usados
colorear(t,sol,0,n); // Invocación al algoritmo
}
Esta función invocación prepara el terreno y luego llama a la función recursiva, pasándole una tupla t donde ir armando las soluciones posibles y sol para guardar la mejor solución encontrada. Esta misma tupla sol se usará para comparar con las tuplas que se van encontrando, de forma de saber si encontramos una mejor solución o no. El tercer parámetro es el primer país sobre el cual comenzar a trabajar, n la cantidad de países total, de forma que el algoritmo puede saber en que momento llega a asignar colores a todos los países y debe detenerse, y k la cantidad de colores para realizar las pruebas con los colores disponibles.
Veamos un ejemplo de la función recursiva colorear:
/* Noten que la tupla sol es pasada por referencia, de modo que cualquier estado de la recurrencia puede modificarla y es visible para todos los demás estados. */
void colorear(tupla t, tupla &sol, int i, int n, int k) {
/* Reestriccion implicita, verificamos que al colocar el color en esta posición
no queden dos paises adyacentes con el mismo color. */
if (Factible(t,i))
if (EsMejor(t,sol))
if (EsSolucion(t,i)) {
Copiar(sol, t)
} else {
for (int color=1; color <= k, color++)
colorear(AsignarColor(t,i,color),sol, i+1, n, k);
}
}
Utilizamos una seria de funciones auxiliares.
Factible: Indica si la tupla t, con colores asignados hasta la posición i no contiene países adyacentes con el mismo color.
EsMejor: Indica si la cantidad de colores utilizados en t es menor que los de sol.
EsSolucion: Indica si se completo la cantidad de países a colorear. Si es así (y como antes vimos que era mejor esta solución que la de sol) procedemos a copiar la misma en sol.
AsignarColor: Como todavía no completamos la cantidad de países debemos asignar un color de los k disponbles al país i, y continuar con la recursión.
Los detalles importantes a tener en cuenta son algunos como que la tupla sol puede ser modificada copiando el contenido de t sobre ella por cualquier paso recursivo que encuentre una mejor solución que la que tenemos hasta el momento. Claro que cuando sol es vacía debemos tener cuidado para no tener una solución vacía como la mejor encontrada. Otro detalle importante es no perder soluciones posibles, por eso en cada paso intentamos asignar todos los colores a cada país, para luego en la nueva llamada verificar la adyacencia.
Una posible implementación de AsignarColor, teniendo en cuenta la estructura de tupla que definimo podría ser:
tupla Asignarcolor(tupla t, int, i, int color) {
t.colores[i] = color;
t.cantVeces[color] = t.cantVeces[color]+1; // Incrementamos la cantidad de veces que usamos el color
if (t.cantVeces[color] == 1)
t.cantColores = t.cantColores +1; // Si el color asignado no habia usado aun, incrementamos cantColores
return t;
}
Este algoritmo construido con Backtracking nos permite generar todas las combinaciones posibles de colores asignados, optimizando de forma que podemos detener la recursión en un paso intermedio al encontrar dos países adyacentes con el mismo color.
En la próxima entrada veremos otro ejemplo de Backtracking similar implementado.
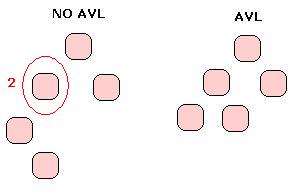
Los árboles binarios tienen la utilidad de ordenar la información, separando el conjunto en dos posibilidades, izquierda y derecha, por lo que reducimos el conjunto de búsqueda a la mitad en cada paso. Esto nos lleva a que en un árbol balanceado (si tiene las ramas izquierda y derecha del mismo tamaño +1 o -1) tenemos una altura de Log(n), lo cual hace que las búsquedas sean «rápidas». El problema que tienen los árboles comunes es que pueden degenerar rapidamente en una lista, por ejemplo si insertamos el elemento 1 como raíz, y luego insertamos los números 2, 3, 4, 5… Tendremos inserciones siempre a la derecha, lo que nos lleva a tener una estructura de lista perdiendo la utilidad de dividir a la mitad en cada paso. Para solucionar esto utilizaremos los AVL, o árboles binarios balanceados, que nos permiten después de cada inserción rotar los nodos de forma de que quede ordenado.
Los AVL utilizan el factor de balanceo para decidir si es necesario rotar una rama luego de insertar. Este FB (factor de balanceo) nos dice la diferencia de alturas entre el subárbol izquierdo y el derecho, por lo que restando las alturas de los mismos obtenemos este valor.
En el primer ejemplo del caso anterior tenemos que la primer rama izquierda tiene un desbalanceo, ya que la altura de su subrama izquierda es 2, y la de la derecha es 0, lo que nos da: FB = 2. Tenemos desbalance. En el segundo caso el FB no supera el valor 1, por lo que no hay necesidad de rotar.
Las rotaciones se dividen en dos casos, simples o dobles. Las simples se conocen como LL si son de la rama izquierda, y RR si son de la rama derecha. Las rotaciones dobles son LR o RL, ya que son combinadas y más complejas como sugiere su nombre. Vemos primero las rotaciones simples.
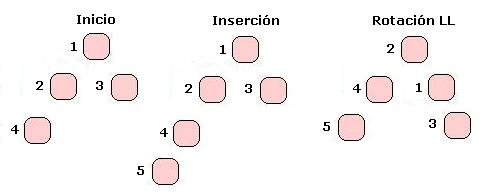
En el caso simple LL, tomemos un nodo 1 que quedará con FB = 2, insertamos un nodo en el subárbol izquierdo de su hijo izquierdo, con lo que tenemos una inserción en la izquierda-izquierda (por eso Left Left). Para balancear el árbol deberemos tomar el hijo izquierdo de 1 (llamémoslo 2), y ponerlo como padre de 1, el hijo derecho de 1 queda en su lugar, el hijo izquierdo de 2 queda en su lugar y el hijo de derecho de 2 debe ir como hijo izquierdo de 1, ya que en su lugar tendremos a 1. Veamos un dibujo:
Lo que hacemos es mover el subárbol que queda con un largo excesivo hacia arriba, sacando al padre para hacer lugar, teniendo cuidado eso si de mantener la relación de mayor menor, lo cual hacemos dejando los subárboles izquierdos de 2 y derecho de 1 en sus lugares (ya que son menores que todos los demas, y mayores respectivamente), y moviendo de lugar el subárbol derecho de 2 hacia el izquierdo de 1. Esto lo podemos hacer ya que este subárbol contiene elementos mayores que los de 2, pero menores que 1.
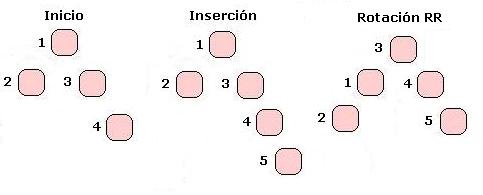
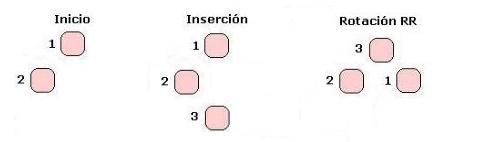
En el caso de la rotación simple RR sucede lo mismo que acabamos de ver, solo que en el caso de insertar a la derecha del hijo derecho:
Hemos visto los dos casos simples, donde insertamos en la rama menor que todos o mayor que todos. Veremos ahora que sucede cuando insertamos en el hijo derecho del subárbol izquierdo, o en el izquierdo del derecho, es decir cruzado.
En este caso lo que haremos será aplicar dos rotaciones simples, con lo cual haremos que el nodo insertado «suba» acortando la altura del árbol. Noten que el nodo que tiene FB = 2 es el nodo 1, y no el nodo 2 que es donde insertamos (en su subárbol derecho). Por lo cual deberemos modificar la altura de sus hijos para reducir el FB a 1.
El proceso que seguiremos será el siguiente, tomamos el nodo en la rama donde se generó el desbalance, en este caso el 2, como la inserción es en el fijo derecho de 2, tomamos este nodo (el 3), y lo guardamos como la nueva raiz. Guardamos los dos hijos del 3 (ya que en realidad el árbol puede ser más amplio, y haber nodos hacia «abajo») y ponemos como su hijo izquierdo a 2, y su hijo derecho a 1. Así sabemos que el orden se mantiene, 3, estaba a la derecha de 2, por lo que es mayor, y a la izquierda de 1, por lo que es menor. Colocado 3 en el lugar de 1, tomamos los dos posibles hijos de 3 que guardamos y los colocamos respectivamente como hijo derecho de 2 al hijo izquierdo, y como hijo izquierdo de 1 al derecho de 3. Otra vez manteniendo el orden.
Veamos un ejemplo gráfico:
En resumen la idea es, cuando detectamos que un nodo tiene FB = 2 (recuerden, en valor absoluto), entonces de acuerdo a sea positivo o negativo tomamos la rama izquierda o la derecha, subimos el nodo correspondiente y reasignamos con cuidado los hijos para no perder el orden. Las operaciones LR y RL, como las LL y RR son simétricas, por lo que el código será idéntico cambiando el hijo seleccionado. Como mencionabamos antes, las operaciones complejas se pueden reducir a dos operaciones simples, por ejemplo la LR podemos reducrila a realziar primero una RR en el hijo izquierdo y luego una LL en la raíz.
Pasemos a los ejemplos de código en C para ver como implementar estas rotaciones.
Lo primero que tenemos que hacer, es hacer una modificación al tipo de dato de árbol binario, ya que queremos tener en cuenta el FB en cada nodo, para detectar un desbalance. Agregaremos un campo int con la altura del nodo actual, lo cual nos permite saber sin tener que sumar recursivamente cada vez la altura de un nodo con sus hijos:
struct AVLNode {
int dato;
AVLNode izq;
AVLNode der;
int altura;
};
El siguiente paso es agregar una función que nos permite conocer la altura de un nodo actual, de forma que nuestro TAD quede bien estructurado, y en caso de ser necesario poder actualizar la misma calculando el FB:
Como ven, pasamos la raíz por referencia, de forma que podemos modificar el puntero y colocar su hijo derecho en su lugar. Pero primero tenemos cuidado de copiar los datos necesarios para no perder las referencias, y de actualizar las alturas correspondientes. Ahora veamos el caso de la rotación doble, para la cual usaremos el hecho de que podemos descomponer la misma en dos rotraciones simples.
Primero realizamos una LL y luego una RR, RotarAVLIzq es la rotación simple en el hijo izquierdo, análoga a RotarAVLDer que acabamos de ver pero sobre el hijo izquierdo de la raíz.
Con esto tenemos las operaciones básicas para balancear, crearemos una funcion que nos permita balancear cuando lo necesitemos, y luego veremos la de inserción que será simple ya que tenemos las tareas divididas en nuestro TAD AVL.
void BalancearAVL (AVLNode* t) {
if(t != NULL) {
if (Altura(t->izq) – Altura(t–>der) == 2) { /* FB indica izquierda */
if (altura (t->izq->izq) >= altura (t->izq->der))
/* simple hacia la izquierda */
RotarAVLIzq(t);
else
/* doble hacia la izquierda */
RotarAVLIzqDoble(t);
}
void InsertarAVL (AVLNode* t, int x) {
if (t == NULL) {
t = ArbolCrearAVL();
ArbolInsertar(t,x);
} else {
if (x < ArbolRaiz(t))
InsertarAVL(&t->izq, x);
else
InsertarAVL(&t->der, x);
BalancearAVL(t);
AlturaCalcular (t);
}
}
Al insertar buscamos la posición del elemento como lo hacemos normalmente en un árbol binario, buscando en derecho o izquierda de acuerdo a la comparación. Una vez que encontramos su posición creamos un nuevo nodo y lo insertamos, al regresar de la recursión debemos balancear los nodos ya que podríamos haber creado un desbalance, actualizando la altura según corresponda.
Con esto completamos nuestro TAD AVL, como ya dijimos tenemos la capacidad de ordenar el árbol y asegurarnos que el orden de búsqueda de un elemento no supere nunca Log(n). Un buen ejercicio de multiestructuras es pensar en la combinación de un AVL con una lista, de forma que podamos buscar determinado valor dentro del AVL, y luego a partir de ese valor podamos recorrer una cantidad de valores ordenados sin tener que buscar cada uno.
Supongamos que tenemos tiempos ordenados en un AVL, y queremos obtener los 10 tiempos siguiente a partir de cierto momento. Entonces lo que podemos hacer es tener un AVL «espejado» en una lista, con lo cual podemos buscar el tiempo deseado en el AVL (o el más cercano a él), y luego de encontrar el mismo saltamos a la lista (mantendremos un puntero a la posición correspondiente en cada nodo del AVL) y recorremos la lista obteniendo los 10 elementos. Así logramos un buen grado de eficiencia, teniendo únicamente que buscar un tiempo en el AVL con un orden Log(n) y luego recorriendo la lista que ya sabemos esta ordenada ya que mantenemos el orden al hacer cada inserción.
En la próxima entrada veremos las tablas de dispersión o Hash, los cuales nos permite hacer búsquedas en un tiempo constante.
La estructura de datos que veremos es la de árboles, esta estructura nos permite organizar información de forma que tenemos una relación de padres e hijos, ordenando por ejemplo por un valor.En el primer caso veremos el árbol binario de búsqueda, donde cada nodo tiene dos ramas y un campo de valor, a la izquierda conectaremos otros nodos de menor valor y a la derecha otros nodos de mayor valor.
Definiremos como NULL un árbol vacío, para cada nodo del árbol tendremos una rama izquierda y una derecha, que son punteros a otros nodos, y un campo para el valor. En este ejemplo usaremos un int para el valor para simplificar, pero podríamos tener un puntero a otra estructura más compleja (y tendríamos que tener forma de poder comparar estos elementos más complejos de forma que podamos ordenar el árbol).
Siguiente la línea de definir un TAD, vamos a crear operaciones básicas sobre esta definición para realizar las tareas esenciales sobre un árbol, como crear, insertar, recorrer y borrar. Por la naturaleza de los árboles tenemos una definición recurrente, y el TAD también trabajará de esta forma, con funciones recursivas sobre la estructura de datos.
Aquí tenemos un TAD para nuestro árbol binario:
arbol * ArbolCrear();
// Crear un árbol vacío.
bool ArbolEsVacio(arbol * t);
// Devuelve true si el árbol ess vacío.
void ArbolInsertar (arbol *& t, int n);
// Inserta el elemento n en el árbol.
int ArbolRaiz(arbol * t);
// Devuelve la raíz del árbol.
arbol * ArbolIzq(arbol * t);
// Devuelve la rama izquierda del árbol.
arbol * ArbolDer(arbol * t);
// Devuelve la rama derecha del árbol.
Y su implementación:
arbol * ArbolCrearVacio() {
return NULL;
}
bool ArbolEsVacio(arbol * t) {
return t == NULL;
}
void ArbolInsertar (arbol *& t, int n) {
if (ArbolEsVacio(t)) {
arbol * nodo = new arbol;
nodo->valor = n;
nodo->izq = ArbolCrearVacio();
nodo->der= ArbolCrearVacio();
t = nodo;
} else {
if (arbol->nodo > n) {
ArbolInsertar (t->izq, n);
} else {
ArbolInsertar (t->der, n);
}
}
}
int ArbolRaiz(arbol * t) {
return t->valor;
}
arbol * ArbolIzq(arbol * t) {
return t->izq;
}
arbol * ArbolDer(arbol * t) {
return t->der;
}
Tengan en cuenta algunos detalles, como por ejemplo al insertar pasamos por referencia el puntero al árbol de forma que podemos modificarlo. Otro detalle es que por ejemplo las operaciones que nos dan las ramas izq y der deben ser utilizadas con precaución, ya que no chequean que el árbol sea vacío. Por lo tanto si llamamos a una de estas operaciones con un árbol vacío tendremos un error grave en el programa. Tenemos que colocar una precondición en el TAD, aclarando que esa operación sólo puede ser utilizada en el caso de que hayamos chequeado que el árbol que le pasamos no es vacio.
arbol * ArbolIzq(arbol * t);
// Devuelve la rama izquierda del árbol.
// Precondición: !ArbolEsVacio(t)
arbol * ArbolDer(arbol * t);
// Devuelve la rama derecha del árbol.
// Precondición: !ArbolEsVacio(t)
Ahora que tenemos el árbol binario podemos organizar información, por ejemplo si tenemos una gran cantidad de numeros y queremos saber si determinado número pertenece al conjunto podemos hacerlo recorriendo el árbol en forma recursiva, chequeando con el nodo actual y recorriendo las ramas. Por ejemplo podríamos hacer algo asi:
Si el nodo en que estamos es vacío, entonces no encontramos el valor buscado, si no es vacío comparamos el valor del nodo actual, si es igual lo encontramos y devolvemos true, si no es igual puede ser mayor o menor por lo que llamamos en forma recursiva a la función con una de las dos ramas para seguir buscando.
Podemos ver que la eficiencia de esta estructura de datos es mucho mayor en las búsquedas, ya que podemos encontrar un elemento sin tener que recorrer todo el conjunto, como nos sucedía en el caso de las listas. Lo que hacemos al buscar en el árbol binario de búsqueda es ir dividiendo el conjunto en dos partes, por lo que cada vez reducimos a la mitad la cantidad de elementos, lo que nos da un orden de búsqueda igual a lograitmo de n, donde n es la cantidad de elementos del conjunto (vermos esto en más detalle más adelante, al finalizar las estructuras y realizar un análisis de órdenes de las mismas).
Por su parte la lista nos obliga a recorrer todo el conjunto de elementos, por lo que podemos tener que recorrer toda la lista para encontrar. Entonces tenemos que para buscar tenemos orden n para la lista, y orden ln(n) para el árbol binario.
Pero no todo es color de rosas en los árboles binarios, ya que tenemos dos complicaciones. La primera es que para insertar un elemento tenemos que recorrer, comparando con los nodos hasta llegar al lugar adecuado del valor dentro del árbol, lo que nos llevar a realizar ln(n) operaciones antes de poder insertar, mientras que con la lista insertamos al comienzo de la misma y no tenemos que recorrer nada, lo que nos da un orden 1 (es decir, una sola operación para insertar sin importar la cantidad de elementos que haya en el conjunto).
El otro problema que tenemos es que no realizamos balanceos del árbol al insertar, a medida que vamos insertando vamos dejando los nodos tal quedan de las comparaciones, pero esto puede provocar que nuestro árbol se transforme en una lista (o en algo parecido a una lista) si se dan ciertas condiciones. Por ejemplo, supongamos que queremos insertar los siguientes números: 10, 8, 6, 4, 2. Entonces siempre estaremos insertando en la rama izquierda, por lo que tendremos en realidad una lista de elementos, no tendremos una distribución pareja de elementos lo cual es necesario para que nuestra búsqueda tenga orden ln(n) (recuerden que este orden se da por ir dividiendo el conjunto en 2 cada vez, reduciendo el tamaño).
Para solucionar este problema veremos en la siguiente entrada, la estructura de datos conocida como AVL, esta estructura sigue la línea del árbol binario que acabamos de ver pero haciendo hincapie en mantener el árbol balanceado en todo momento, es decir que nunca tendremos el problema de que nuestro árbol degenere en una lista y perdamos la posibilidad de buscar en forma rápida dentro del conjunto. Esto lo lograremos rotando las ramas luego de insertar si las mismas quedan desbalanceadas.
Cambiando un poco el objetivo del sitio vamos a investigar un poco sobre las estructuras de datos y algoritmos en C/C++. Para esto vamos a comenzar trabajando con estructuras de datos simples como listas y colas, para luego pasar a estructuras como árboles, árboles binarios de búsqueda, AVLs, Hash y algoritmos complejos.
Para poder seguir los ejemplos les recomiendo utilizar Cygwin si usan Windows para tener todas las herramientas de compilado (g++, archivo make, librerias, etc). Si tienen Linux simplemente instalen los paquetes devel.
Trabajaremos construyendo los tipos abstractos de datos (TADs) que nos permitirán abstraernos de la estructura de punteros y trabajar con operaciones que se encargan de hacer el trabajo sucio =). Esto nos libera de estar revisando detalles de la estructura para poder concentrarnos en como resolver problemas.
Comenzaremos trabajando con las dos estructuras más simples, listas y colas. En las dos estructuras de datos encadenamos elementos en forma simple, la diferencia está en la forma en que una vez que ingresamos los mismos, luego podemos sacarlos. En la lista insertamos en la cabeza y sacamos elementos desde la misma cabeza, este orden es conocido como último en entrar, primero en salir (LIFO siglas en inglés). En el caso de la cola utilizamos el otro orden, primero en entrar primero en salir (FIFO siglas en inglés).
Veamos la definición del tipo de datos para la lista:
typedef struct lista {
int valor;
lista * sig;
};
Con esta definición podemos ir enlazando los nodos de la lista, poniendo en el último el valor NULL en el puntero a sig indicando que termina la lista.
El siguiente paso es definir la lista de operaciones con las cuales vamos a poder trabajar sobre este tipo de datos. Definiremos las siguientes funciones:
lista * ListaCrearVacia();
// Crear una lista de nodos vacia.
bool ListaEsVacia(lista * l);
// Devuelve true si la lista es vacia y false en caso contrario.
void ListaAgregar (lista *& l, int n);
// Agrega el elemento n al comienzo de la lista.
int ListaPrimero(lista * l);
// Devuelve el primer elemento de la lista.
lista * ListaResto(lista * l);
// Devuelve un alias al resto de la lista.
void ListaDestruir(lista * l);
// Libera la memoria asociada a la lista.
Dadas estas operaciones podremos trabajar sobre el tipo de datos con comodidad, creando, insertando, recorriendo y eliminando la estructura sin necesidad de preocuparnos por los punteros que la componen. Por ejemplo si queremos recorrer una lista que tiene elementos podríamos hacer lo siguiente (debemos verificar que no sea vacia primero):
while (!ListaEsVacia(listaDatos)) {
int valor = ListaPrimero(listaDatos);
printf(«\nDato: %d»,valor);
listaDatos= ListaResto(listaDatos);
}
Noten que deberíamos guardar una copia del puntero inicial de la lista para poder volver a recorrerla o bien poder eliminar la memoria de la misma. Si no tenemos este puntero habremos perdido el comienzo de la lista =P.
Entrando un poco en la construcción del TAD, en el caso de la lista tendremos que insertar el elemento al principio de la misma, mientras que en la cola insertamos al final. Esto nos lleva a ver en el caso de la lista si insertamos al comienzo podremos hacerlo rápidamente aunque la lista sea muy grande. Simplemente modificaremos la cabeza de la lista y pondremos el nuevo dato como comienzo. Veamos un ejemplo:
void ListaAgregar (lista *& l, int n) {
lista* nuevoNodo = new lista;
nuevoNodo->valor = n;
nuevoNodo->sig = l;
l = nuevoNodo;
return;
}
Lo que hacemos es crear el nuevo nodo, asignar el valor de entero y luego encadenamos la lista «vieja» como siguiente elemento del nuevo nodo. Esto nos deja la lista l con el nuevo nodo al comienzo.
La definición de las otras funciones es simple, veamos algunas:
lista * ListaCrearVacia() {
lista* l = NULL;
return l;
}
bool ListaEsVacia(lista * l) {
return l == NULL;
}
int ListaPrimero(lista * l) {
return l->valor;
}
lista * ListaResto(lista * l) {
return l->sig;
}
Pero pensemos por un momento en el caso de la cola, para insertar al final tendremos que ir hasta el final de la misma, por lo cual en caso de que tengamos una gran cantidad de datos tendremos que recorrer muchos nodos. Esto no es bueno, como veremos más adelante buscaremos que nuestras estructuras de datos sean eficientes y sean «más lentas» cuantos más datos tengamos en las mismas. Si nuestra estructura se vuelve más lenta a medida que tenemos más datos sufriremos consecuencias a largo plazo, nuestro programa será cada vez más lento.
Para solucionar este problema lo que haremos será tener un puntero al comienzo y otro al final de la cola, lo cual nos permitirá insertar al final de la misma y acceder al comienzo en forma directa, sin tener que recorrer la misma.
typedef struct cola {
lista * inicio;
lista * fin;
};
Noten que utilizaremos la lista, pero con un nodo especial que nos permita acceder al comienzo y al fin de la misma para remover e insertar respectivamente. Las funciones del TAD nos darán las operaciones que podremos utilizar para trabajar sobre este tipo de datos sin preocuparnos de punteros y demás:
cola * ColaCrearVacia();
// Crea una cola vacia.
bool ColaEsVacia(cola * c);
// Devuelve true si la cola es vacia y false en caso contrario.
void ColaEncolar (cola * c, int n);
// Agrega el elemento n a la cola.
int ColaPrimero(cola * c);
// Devuelve el primer elemento de la cola.
void ColaDesencolar(cola * c);
// Elimina el primer elemento de la cola.
void ColaDestruir(cola * c);
// Libera la memoria asociada a la cola.
Para estas operaciones utilizaremos prácticamente el mismo código que para la lista, únicamente teniendo cuidado de utilizar los «accesos directos» según el caso que corresponda, para evitar tener que recorrer toda la cola.
En la próxima entrada veremos árboles binarios de búsqueda, los cuales permiten ordenar la información para encontrar en forma más rapida la misma =)